Decompile entire PDFs into real HTML — every page rendered, stitched into one continuous-flow document. Every img, table, p is a real DOM node. $$('h1') returns headings across all pages.
Powered by Gemini 3.5 Flash one-shot rebuild + lossless extract_image(xref) via PyMuPDF + 600 DPI vector fallback. ~20-50 seconds per page, 3 pages in parallel. ~$0.005-$0.01 per page.
?init=$$('section.pdf-page').length + ' pages, ' + $$('h1,h2,h3').length + ' headings'
$$('.author').map(a => ({name, email}))
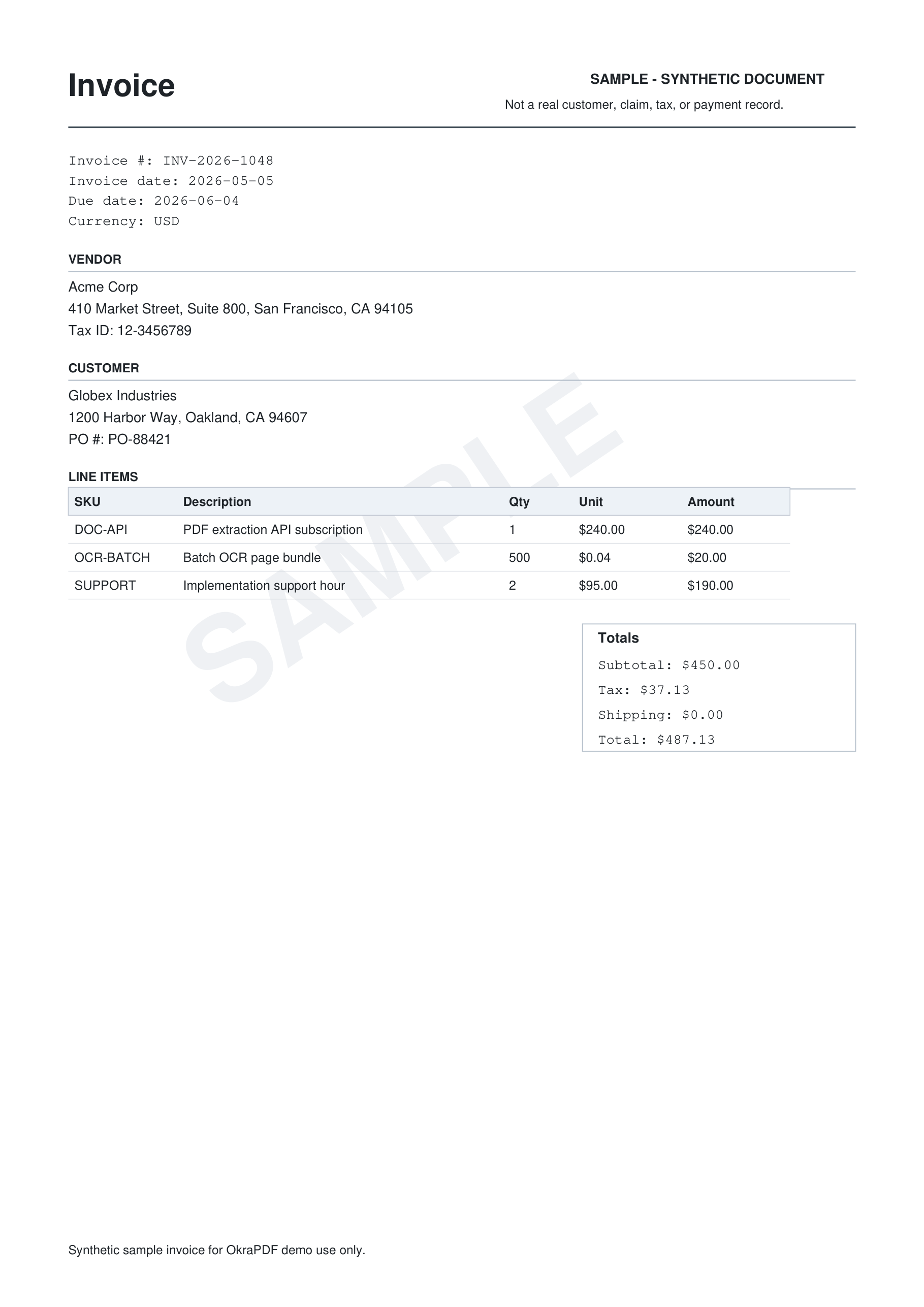
$$('tbody tr').map(r => ({SKU, Description, Qty, Unit, Amount}))
$$('img').map(i => i.alt) → every figure across the report
$$('h1,h2,h3').map(h => h.tagName + ' ' + h.textContent.trim())
$$('p').length + ' paragraphs across all pages'